File I/O
Unbuffered I/O
- open
- read
- write
- lseek
- creat
- close
- dup, dup2
The term unbuffered means that each read or write invokes a system call in the kernel. These unbuffered I/O functions are not part of ISO C, but are part of POSIX.1 and the Single UNIX Specification.
Buffered I/O
- fopen
- fread
- fwrite
- fseek
- fclose
The standard I/O library handles such details as buffer allocation and performing I/O in optimal-sized chunks, obviating our need to worry about using the correct block size. This makes the library easy to use, but at the same time introduces another set of problems if we’re not cognizant of what’s going on.
Implementation details of buffered I/O.
Next sample implementation code copy from Section 8.5 of KR, The C Programming Language.
#define NULL 0
#define EOF (-1)
#define BUFSIZ 1024
#define OPEN_MAX 20 /* max #files open at once */
typedef struct _iobuf {
int cnt; /* characters left */
char *ptr; /* next character position */
char *base; /* location of buffer */
int flag; /* mode of file access */
int fd; /* file descriptor */
} FILE;
extern FILE _iob[OPEN_MAX];
#define stdin (&_iob[0])
#define stdout (&_iob[1])
#define stderr (&_iob[2])
enum _flags {
_READ = 01, /* file open for reading */
_WRITE = 02, /* file open for writing */
_UNBUF = 04, /* file is unbuffered */
_EOF = 010, /* EOF has occurred on this file */
_ERR = 020 /* error occurred on this file */
};
int _fillbuf(FILE *);
int _flushbuf(int, FILE *);
#define feof(p) ((p)->flag & _EOF) != 0)
#define ferror(p) ((p)->flag & _ERR) != 0)
#define fileno(p) ((p)->fd)
#define getc(p) (--(p)->cnt >= 0 \
? (unsigned char) *(p)->ptr++ : _fillbuf(p))
#define putc(x,p) (--(p)->cnt >= 0 \
? *(p)->ptr++ = (x) : _flushbuf((x),p))
#define getchar() getc(stdin)
#define putcher(x) putc((x), stdout)
#define PERMS 0666 /* RW for owner, group, others */
FILE *fopen(char *name, char *mode)
{
int fd;
FILE *fp;
if (*mode != 'r' && *mode != 'w' && *mode != 'a')
return NULL;
for (fp = _iob; fp < _iob + OPEN_MAX; fp++)
if ((fp->flag & (_READ | _WRITE)) == 0)
break; /* found free slot */
if (fp >= _iob + OPEN_MAX) /* no free slots */
return NULL;
if (*mode == 'w')
fd = creat(name, PERMS);
else if (*mode == 'a') {
if ((fd = open(name, O_WRONLY, 0)) == -1)
fd = creat(name, PERMS);
lseek(fd, 0L, 2);
} else
fd = open(name, O_RDONLY, 0);
if (fd == -1) /* couldn't access name */
return NULL;
fp->fd = fd;
fp->cnt = 0;
fp->base = NULL;
fp->flag = (*mode == 'r') ? _READ : _WRITE;
return fp;
}
/* _fillbuf: allocate and fill input buffer */
int _fillbuf(FILE *fp)
{
int bufsize;
if ((fp->flag&(_READ|_EOF_ERR)) != _READ)
return EOF;
bufsize = (fp->flag & _UNBUF) ? 1 : BUFSIZ;
if (fp->base == NULL) /* no buffer yet */
if ((fp->base = (char *) malloc(bufsize)) == NULL)
return EOF; /* can't get buffer */
fp->ptr = fp->base;
fp->cnt = read(fp->fd, fp->ptr, bufsize);
if (--fp->cnt < 0) {
if (fp->cnt == -1)
fp->flag |= _EOF;
else
fp->flag |= _ERR;
fp->cnt = 0;
return EOF;
}
return (unsigned char) *fp->ptr++;
}
Buffer
In fact, no matter unbuffered I/O or buffered I/O they both have buffer layer before data be writed into disk eventually. For unbuffered I/O, kernel will maintain a buffer. User process call write and return immediately, the data in fact pending on kernel buffer and will be flush to disk asynchronous.
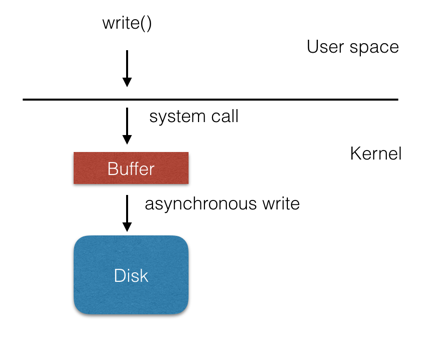
For buffered I/O, there are two layer buffer, both glibc and kernel maintain two independent buffer.
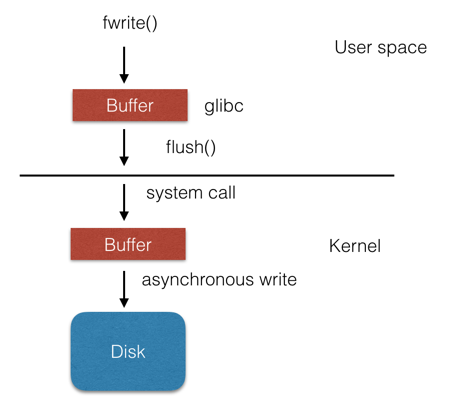
Standard library buffer
Standard I/O library providing three types of buffering.
- Fully buffered. In this case, actual I/O takes place when the standard I/O buffer is filled.
- Line buffered. In this case, the standard I/O library performs I/O when a newline character is encountered on input or output
- Unbuffered. Standard I/O library dose not buffer the characters.
ISO C requires the following buffering characteristics:
Standard input and standard output are fully buffered, if and only if they do not refer to an interactive device.
Standard error is always unbuffered
All other streams are line buffered if they refer to a terminal device; otherwise, they are fully buffered.
File I/O Efficiency
We will compare the efficiency of Unbuffered I/O, sync I/O and Buffered I/O.
Unbuffered I/O
#include "apue.h"
#define BUFFSIZE 4096
int
main(void)
{
int n;
char buf[BUFFSIZE];
while ((n = read(STDIN_FILENO, buf, BUFFSIZE)) > 0)
if (write(STDOUT_FILENO, buf, n) != n)
err_sys("write error");
if (n < 0)
err_sys("read error");
exit(0);
}
Chose the right BUFFSIZE value is extremely important for unbuffered I/O, Next Figure shows the results for reading a 517MB file, using 20 different buffer sizes.
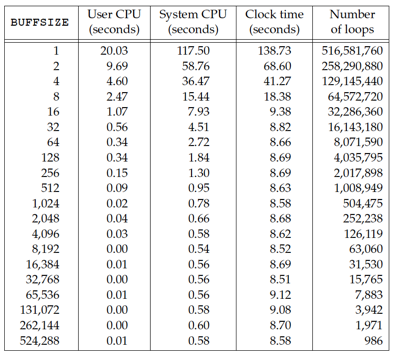
The best result is 4096 byte which just the same as the block size of Linux ext4 file system that be used in this test.
Increasing the buffer size beyond this limit has little positive effect.
sync write
If we add the line
#include <fcntl.h>
fcntl(STDOUT_FILENO, F_SETFL, O_SYNC)
we’ll turn on the synchronous write flag. This causes each write to wait for the data to be written to disk before returning. Normally in the UNIX System, a write only queues the data for writing; the actual disk write operation can take place sometime later. A database system is a likely candidate for using O_SYNC , so that it knows on return from a write that the data is actually on the disk, in case of an abnormal system failure.
Test on Linux ext4
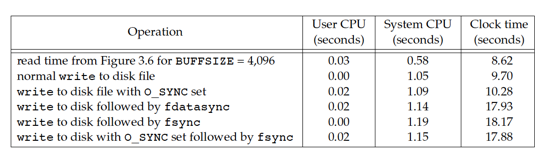
The six rows in Figure were all measured with a BUFFSIZE of 4,096 bytes. The results in above Figure were measured while reading a disk file and writing to /dev/null , so there was no disk output. The second row in this Figure corresponds to reading a disk file and writing to another disk file. This is why the first and second rows are different. The system time increases when we write to a disk file, because the kernel now copies the data from our process and queues the data forwriting by the disk driver.
When we enable synchronous writes, the system and clock times should increase significantly. As the third row shows, the system time for writing synchronously is not much more expensive than when we used delayed writes. This implies that the Linux operating system is doing the same amount of work for delayed and synchronous writes (which is unlikely), or else the O_SYNC flag isn’t having the desired effect.
Next we run the same the on Mac OSX.
Test on Mac OSX HFS
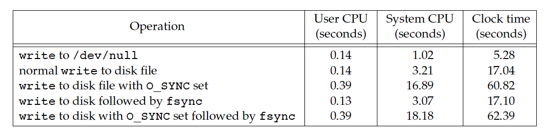
Note that the times match our expectations: synchronous writes are far more expensive than delayed writes, and using fsync with synchronous writes makes very little difference. Note also that adding a call to fsync at the end of the delayed writes makes little measurable difference. It is likely that the operating system flushed previously written data to disk as we were writing new data to the file, so by the time that we called fsync , very little work was left to be done.
From these two tests, we can see sync write perform some distinguish actions on different system.
Buffered I/O
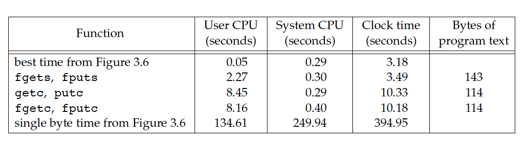
Standard library version has higher User CPU times, because have a loop that is executed 100 million times and the read version it's loop executed only 25,224 times(for a buffer size of 4096).
The system CPU time is about the same as before, because roughly the same number of kernel requests are being made.One advantage of using the standard I/O routines is that we don’t have to worry about buffering or choosing the optimal I/O size.
The last clock time of the first two rows is about the same , because the times spent waiting for I/O to complete.
Conclusion
Compare the benchmark result of these three I/O methods, we can conclude that read for a buffer size of 4096 and standard I/O library has best performance. Although read for a buffer size of 4096 is a bit better, standard I/O still is our best choice, because of easy for coding, we don't have to worry about buffering or choosing the optimal I/O size.
dup, dup2
The new file descriptor returned by dup is guaranteed to be the lowest-numbered available file descriptor. With dup2 , we specify the value of the new descriptor with the fd2 argument. If fd2 is already open, it is first closed. If fd equals fd2 , then dup2 returns fd2 without closing it.
#include <unistd.h>
int dup(int fd);
int dup2(int fd, int fd2);
The new file descriptor that is returned as the value of the functions shares the same file table entry as the fd argument.
The kernel data struct after dup.
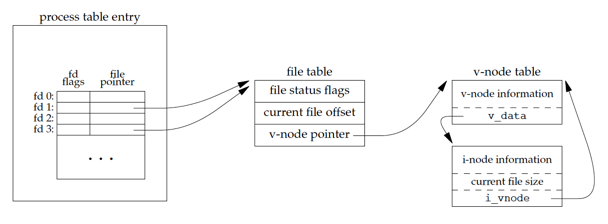
In this figure, we assume that when it’s started, the process executes
newfd = dup(1);
We assume that the next available descriptor is 3 (which it probably is, since 0, 1, and 2 are opened by the shell). Because both descriptors point to the same file table entry, they share the same file status flags—read, write, append, and so on—and the same current file offset.
daemon
The following sequence of code has been observed in various daemon() function.
if ((fd=open("/dev/null", O_RDWR, 0)) != -1) {
dup2(fd, STDIN_FILENO);
dup2(fd, STDOUT_FILENO);
dup2(fd, STDERR_FILENO);
if (fd > STDERR_FILENO) {
close(fd);
}
return NP_OK;
} else {
return NP_ERROR;
}
dup2 be used at here to redirect stdin, stdout and stderr to /dev/null.